
What is Labelled Data in Machine Learning? A 2025 Guide with Real-World Examples
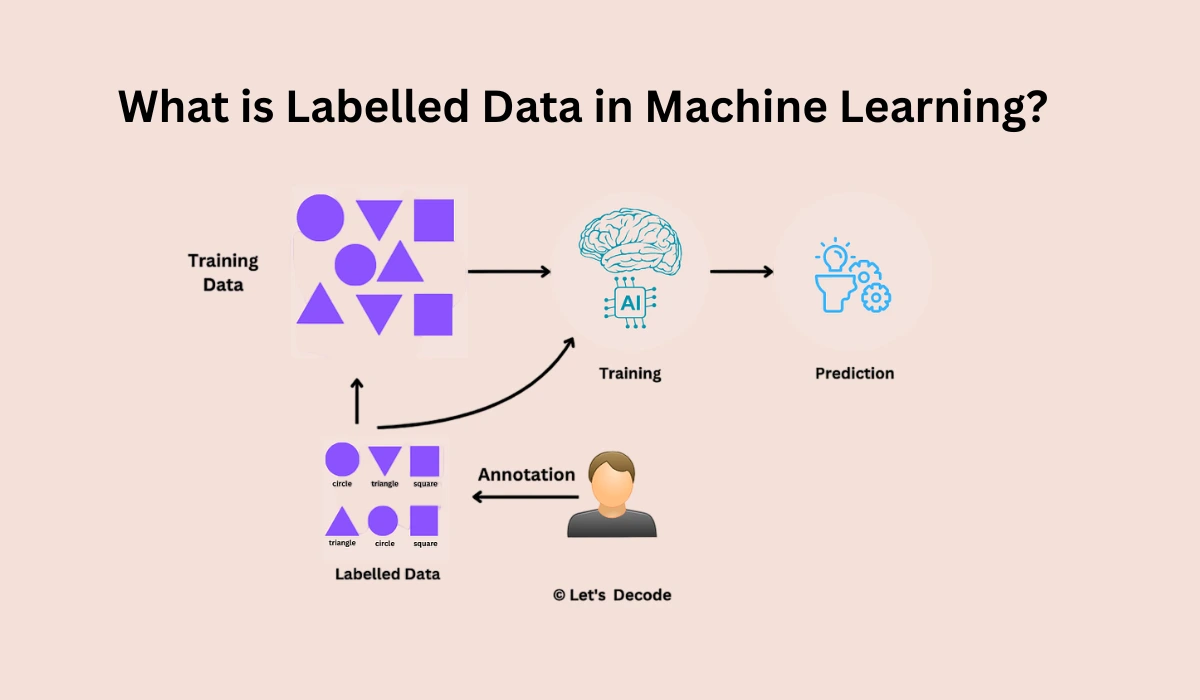
Labelled Data in Machine Learning is a crucial aspect of modern machine learning, particularly in machine learning models that rely on supervised learning. Simply put, labeled data refers to data wherein each unit of data comes with a specific answer, or label. This helps machine learning algorithms train and formulate accurate predictions.
Our comprehensive guide will cover “what labeled data is”, how it works, why it is so important, how it can be used, real-life examples, trends in 2025, and much more. So without further ado, let’s get started!
What is Labelled Data in Machine Learning?
As noted above, labeled data refers to data. In this case, datasets containing input features must be associated with the output or answer. Take for instance a scenario wherein an image has to be classified. A labeled dataset might contain images of the cat, dog, and horse as well as labels corresponding to each of the animals.
Furthermore, these labels enable algorithms to retrieve relevant data essentially provisioned for Multiple Label Classification.
How Labeled Data Work
When you train a machine learning model, labeled data is a teacher:
- Input: The model receives an input (e.g., an image or text).
- Learning: It predicts the label.
- Correction: The model’s prediction is compared to the true label.
- Adjustment: Errors are corrected using optimization techniques like gradient descent.
Over time, the model improves its ability to predict accurately because it “learns” from the labeled examples.
The Importance of Labeled Data in Machine Learning
In 2025, labeled data will remain the backbone of most machine learning systems, especially supervised learning models. Here’s why labeled data is crucial:
- Training Accuracy: Models trained with high-quality labeled data are far more accurate.
- Supervised Learning: Algorithms like classification, regression, and object detection rely entirely on labeled datasets.
- Evaluation: Model performance is evaluated using labeled validation and test datasets.
- Bias Reduction: Well-labeled and diverse data reduce bias and improves fairness.
Google Research states that models trained on diverse labeled data show 30% higher generalization performance across unseen tasks.
Real-World Examples of Labelled Data in Machine Learning
| Industry | Application | Labeled Data Example |
| Healthcare | Medical Image Diagnosis | MRI scans labeled as “Tumor” or “Healthy” |
| Automotive | Self-Driving Cars | Road images labeled with “Pedestrian,” “Stop Sign,” “Vehicle” |
| Retail | Product Recommendation | User purchase histories labeled as “Interested” or “Not Interested” |
| Banking | Fraud Detection | Transaction records labeled “Fraud” or “Legitimate” |
| Social Media | Content Moderation | Posts labeled as “Spam,” “Harassment,” or “Safe” |
Manual vs. Automated data labeling
Manual labeling
- Humans manually review and tag each data point.
- High accuracy but slow and expensive.
Automated labeling
- AI models or software tools pre-label data.
- Fast and scalable, but prone to occasional errors.
Comparison table:
| Criteria | Manual Labeling | Automated Labeling |
| Accuracy | High | Moderate to High |
| Speed | Slow | Fast |
| Cost | Expensive | Cost-Effective |
| Scalability | Limited | Highly Scalable |
Latest Trend (2025): Hybrid approaches where automated tools pre-label data and humans verify the labels are becoming the industry standard.
Best Data Labelling Tools in 2025
Here are the top tools widely used for data labeling in 2025:
- Labelbox: Enterprise-grade data labelling.
- Snorkel AI: Programmatic labeling for large datasets.
- SuperAnnotate: For complex computer vision tasks.
- Amazon SageMaker Ground Truth: Scalable labeling with human-in-the-loop.
- Scalable AI: Fast labeling for autonomous systems.
These tools offer automated, manual, and hybrid labeling capabilities, allowing faster project turnaround times.
The future of Labeled Data in AI
While the need for labeled data remains, the AI world is moving towards:
- Self-Supervised Learning: Models learn from unlabeled data by generating pseudo-labels.
- Few-Shot Learning: Models generalize well even with very few labeled examples.
- Synthetic Data: Artificially created data, fully labeled, reducing dependency on real-world collections.
In the coming years, labeled data will become more critical for specialized tasks, while foundational models will rely less on manual labeling.
FAQs About Labeled Data
Conclusion
Labeled data will always remain the backbone of contemporary machine learning systems. In 2025, although self-supervised learning approaches are gaining traction, the need for meticulously curated labeled datasets remains unmatched.
From healthcare to self-driving cars, from retail to finance, neglecting the quality of annotated data in your AI initiatives can prove detrimental and may even compromise the project’s success.





